6.4 R 7 2.9 R
vaxvolunteers
Mar 12, 2026 · 4 min read
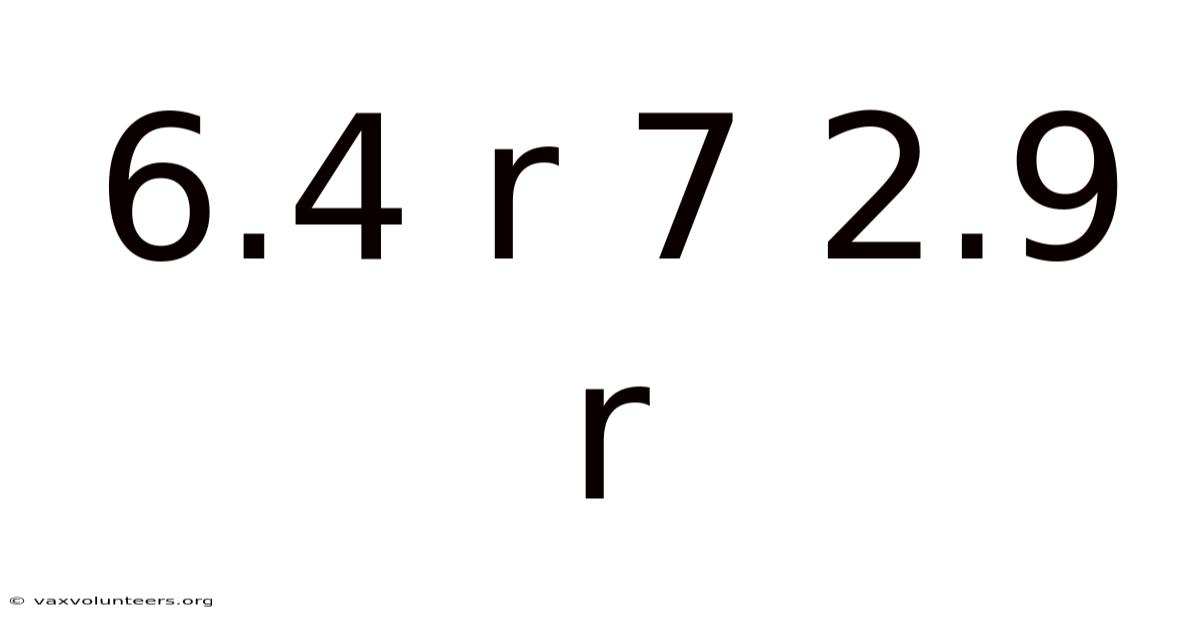
Table of Contents
Understanding Correlation Strength: Decoding r = 0.64 vs. r = 0.29
In the language of statistics and data science, few concepts are as widely used—and as frequently misunderstood—as the correlation coefficient, denoted by the letter r. When you encounter expressions like "6.4 r 7 2.9 r," it represents a critical moment of interpretation, though the notation itself is unconventional. This phrasing likely intends to compare two hypothetical or observed correlation values: one of approximately 0.64 and another of approximately 0.29. These numbers are not just abstract figures; they are the quantitative heartbeat of relationships between variables, telling us how strongly two things move together. This article will transform these simple digits into a comprehensive understanding of correlation strength, moving from basic definition to nuanced application, ensuring you can confidently interpret what an r-value of 0.64 truly signifies versus one of 0.29 in any research or analytical context.
Detailed Explanation: What is the Correlation Coefficient?
At its core, the Pearson correlation coefficient (r) is a single number between -1.0 and +1.0 that measures the strength and direction of a linear relationship between two continuous variables. A value of +1.0 indicates a perfect positive linear relationship: as one variable increases, the other increases in a perfectly predictable, straight-line fashion. A value of -1.0 indicates a perfect negative linear relationship: as one variable increases, the other decreases in a perfectly predictable, straight-line fashion. A value of 0.0 suggests no linear relationship at all; the variables are uncorrelated in a linear sense.
The magnitude (absolute value) of r tells us about the strength of this relationship, while the sign (+ or -) tells us about the direction. Therefore, when we see r = 0.64, we interpret it as a moderately strong positive linear relationship. Conversely, r = 0.29 is interpreted as a weak positive linear relationship. The jump from 0.29 to 0.64 is not just a small numerical increase; it represents a substantial leap in the degree to which knowing the value of one variable allows you to predict the value of the other. The "6.4" and "2.9" in the original query are likely typographical errors or misrepresentations, as a valid r cannot exceed 1.0 in absolute value. The meaningful comparison is between the corrected values of 0.64 and 0.29.
Step-by-Step Breakdown: Calculating and Interpreting r
Understanding how r is derived clarifies why its value matters. The calculation, while often done by software, is conceptually based on the covariance of the variables standardized by their individual standard deviations. Here is the logical flow:
- Covariance: First, we assess how the two variables vary together. If above-average values of X tend to occur with above-average values of Y, the covariance is positive. If above-average X tends to occur with below-average Y, it's negative.
- Standardization: Covariance is difficult to interpret because its scale depends on the units of X and Y. To create a unitless measure, we divide the covariance by the product of the standard deviations of X and Y. This standardization process forces the result into the bounded range of -1 to +1.
- Interpretation Framework: Once calculated, we apply a general interpretive guideline (though context is always king):
- |r| ≥ 0.7: Strong correlation.
- 0.3 ≤ |r| < 0.7: Moderate correlation.
- 0.1 ≤ |r| < 0.3: Weak correlation.
- |r| < 0.1: Negligible or no linear correlation.
Using this framework, r = 0.64 falls squarely in the moderate to strong category. It suggests a meaningful, discernible pattern where the variables share a substantial amount of linear variance. r = 0.29, however, is firmly in the weak category. While statistically significant in large datasets, its practical predictive power is limited. The "scatter" of data points around the best-fit regression line is considerable for r=0.29, meaning many exceptions to the general trend exist.
Real-World Examples: Why the Difference Between 0.29 and 0.64 is Critical
The practical implications of this difference are vast across fields.
- In Economics: Consider the relationship between years of education (X) and annual income (Y). A study might find r = 0.64. This is a strong, positive correlation that policy makers can rely on: investing in education is strongly associated with higher average income. The linear model is a useful predictor for population-level trends. Now, consider the correlation between daily coffee consumption (X) and productivity scores (Y), which might yield r = 0.29. While positive, this weak correlation suggests coffee is just one of many minor factors influencing productivity. A company implementing a mandatory coffee policy based on this r would likely see negligible overall impact, as the relationship is too weak to drive significant change.
- In Health Sciences: The correlation between ** LDL cholesterol levels (X) and risk of heart disease (Y)** is typically strong and positive (r > 0.5), forming a cornerstone of medical advice. In contrast, the correlation between a single night's sleep duration (X) and next-day cognitive test score (Y) might be weak (r ≈ 0.2-0.3). This doesn't mean sleep is unimportant—it's a vital, complex biological need—but it illustrates that a single night's deviation is a poor linear predictor of next-day performance due to many other compensating factors (baseline fitness, nutrition, stress, etc.).
Latest Posts
Latest Posts
-
3 3 5 As A Decimal
Mar 12, 2026
-
8 6 As A Mixed Number
Mar 12, 2026
-
A Pair Of Silk Stockings
Mar 12, 2026
-
Is 60 Cents A Dollar
Mar 12, 2026
-
Healthy Newborn Hesi Case Study
Mar 12, 2026
Related Post
Thank you for visiting our website which covers about 6.4 R 7 2.9 R . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
