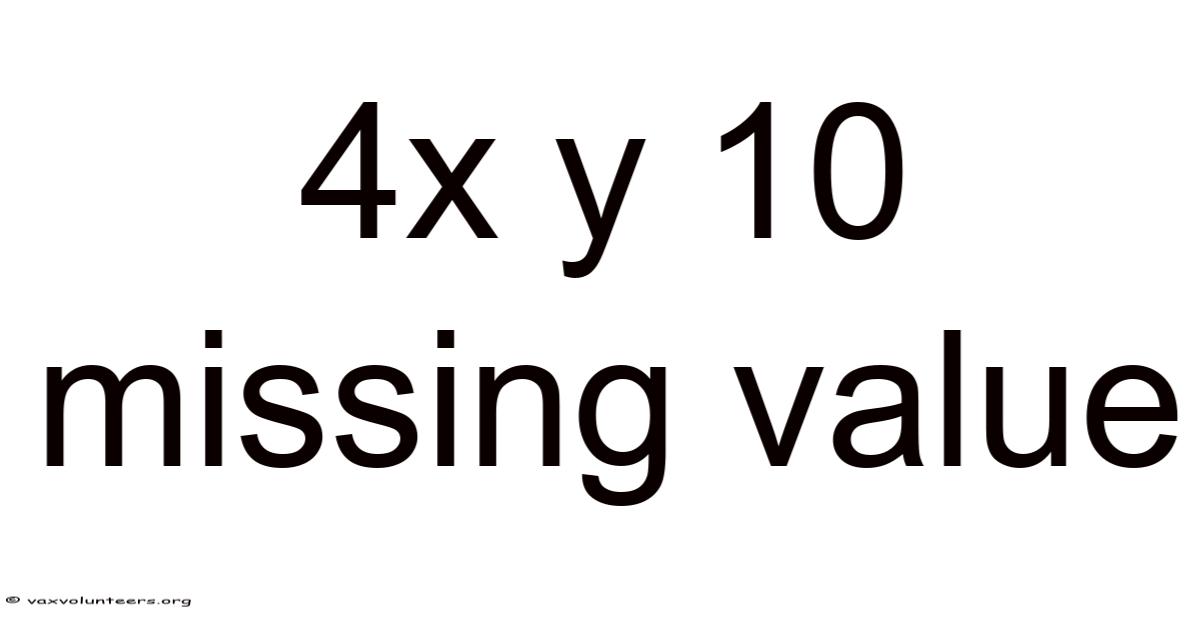
IntroductionWhen you encounter a dataset that includes the notation 4x y 10 missing value, you are looking at a simplified illustration of how missing data can appear in real‑world analysis. In this context, the numbers and letters represent variables or placeholders that may contain gaps – the “missing value” that must be identified, estimated, or handled before any meaningful interpretation can occur. Understanding what a missing value is, why it matters, and how to deal with it is essential for anyone working with data, whether in academic research, business intelligence, or everyday problem‑solving. This article will unpack the concept step by step, provide concrete examples, and equip you with the knowledge to tackle missing data confidently.
Detailed Explanation
The term missing value refers to any observation that was not recorded, was lost, or was deliberately left blank. In statistical terms, a missing value disrupts the completeness of a dataset, which can affect everything from simple descriptive statistics to complex predictive models. The expression 4x y 10 can be read as a mini‑dataset where “4”, “x”, “y”, and “10” are entries that may contain gaps. Take this case: if the value of x or y is absent, the dataset now contains a missing entry that must be addressed.
Missing values arise for many reasons: measurement errors, non‑response in surveys, data entry mistakes, or even intentional anonymization. Practically speaking, they can be completely random (MCAR – Missing Completely At Random), related to observed data (MAR – Missing At Random), or related to unobserved data (MNAR – Missing Not At Random). Recognizing the underlying mechanism is crucial because it determines which imputation or deletion strategy is appropriate That's the part that actually makes a difference..
In practice, a missing value is not simply “nothing”; it is a signal that carries information about the data‑collection process. Ignoring it or treating it as a zero without justification can introduce bias, inflate variance, and lead to misleading conclusions. Which means, a disciplined approach to detecting, summarizing, and resolving missing values is a cornerstone of dependable data analysis.
Step‑by‑Step or Concept Breakdown
Below is a logical workflow you can follow when confronted with a dataset that includes a missing value such as the one implied by 4x y 10 missing value No workaround needed..
- Detect the Missing Entry
- Scan each column for blanks, null symbols, or placeholder text like “NA”, “null”, or an empty cell.
- Use summary functions
1. Detect the Missing Entry
- Programmatic scans – In R use
is.na(),summary(), oranyNA(). In Python’s pandas,df.isnull().sum()quickly tells you how many blanks sit in each column. - Visual checks – Heat‑maps or missing‑value matrices (e.g.,
visdat::vis_miss()in R ormissingno.matrix()in Python) make patterns obvious at a glance. - Metadata review – Sometimes the data‑dictionary will flag fields that are optional or that may be omitted under certain conditions.
2. Quantify the Extent and Pattern
| Metric | Why it matters | Typical tool |
|---|---|---|
| Proportion missing (e.g., 5 % of rows) | Determines whether simple deletion is viable | mean(is.na(column)) |
| Missingness per row | Identifies “sick” records that may need dropping entirely | rowSums(is.na(df)) |
| Correlation of missingness | Detects systematic gaps (e.g., high income respondents skip a question) | Logistic regression of is.na(variable) on other predictors |
| Temporal/Spatial pattern | Pinpoints collection‑phase failures or region‑specific issues | Time‑series plots or GIS heat‑maps |
If the missingness is sparse (< 5 % overall) and appears MCAR, listwise deletion (dropping any row that contains a blank) often suffices. When missingness is higher or exhibits a pattern, more nuanced techniques are required That's the part that actually makes a difference..
3. Choose an Appropriate Handling Strategy
| Strategy | When to use | Core idea | Pros | Cons |
|---|---|---|---|---|
| Listwise (complete‑case) deletion | MCAR, low missing proportion | Remove any record with a missing entry | Simple, retains unbiased estimates under MCAR | Reduces sample size, wastes data |
| Pairwise deletion | Correlation matrices, exploratory analysis | Use all available pairs for each calculation | Maximizes data usage | Can produce inconsistent covariance matrices |
| Mean/Median imputation | Small, MCAR gaps, low‑stakes models | Replace missing with central tendency of that variable | Easy, preserves sample size | Underestimates variance, biases relationships |
| Hot‑deck / k‑Nearest Neighbors (KNN) imputation | MAR, moderate missingness | Borrow values from similar observations | Retains multivariate structure | Computationally heavier, choice of ‘k’ matters |
| Regression imputation | MAR, when strong predictors exist | Predict missing value using a model built on observed data | Leverages relationships among variables | Imputed values are deterministic → underestimates uncertainty |
| Multiple Imputation (MI) | MAR or even MNAR (with auxiliary variables) | Create several plausible datasets, analyse each, then pool results (Rubin’s rules) | Reflects imputation uncertainty, dependable | More complex, requires careful diagnostics |
| Model‑based methods (e.g., EM algorithm, Bayesian hierarchical models) | Complex missingness, especially MNAR | Treat missing values as latent variables within a likelihood framework | Statistically efficient, can incorporate missingness mechanism | Requires strong assumptions, specialized software |
| Indicator method | When missingness itself may be informative | Add a binary flag (is_missing) alongside imputed value |
Captures potential predictive power of missingness | May inflate multicollinearity |
4. Implement the Chosen Method
Below is a concise code snippet for multiple imputation using the popular mice package in R and the IterativeImputer in Python’s scikit‑learn. Both illustrate the “create‑analyse‑pool” workflow.
R (mice)
library(mice)
# 1. Inspect missingness pattern
md.pattern(df)
# 2. Run MI with 5 imputed datasets
imp <- mice(df, m = 5, method = 'pmm', seed = 123)
# 3. Fit model on each completed dataset
fit <- with(imp, lm(outcome ~ x + y + other_covariates))
# 4. Pool results
pooled <- pool(fit)
summary(pooled)
Python (IterativeImputer)
import pandas as pd
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.linear_model import LinearRegression
import statsmodels.api as sm
# 1. Visualise missingness
import missingno as msno
msno.matrix(df)
# 2. Impute
imputer = IterativeImputer(random_state=42, max_iter=10)
df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
# 3. Fit model
X = df_imputed[['x','y','other_covariates']]
X = sm.add_constant(X)
model = sm.OLS(df_imputed['outcome'], X).fit()
# 4. Summarise
print(model.summary())
When you adopt MI, remember to repeat the analysis on each imputed dataset and combine estimates using Rubin’s rules (the pool function in R or the statsmodels combine utilities in Python). This step preserves the variability introduced by the imputation process Small thing, real impact. And it works..
5. Validate the Imputation
- Diagnostic plots – Compare distributions of observed vs. imputed values (
density,boxplot, orqqplot). - Convergence checks – In MI, trace the imputed means across iterations; they should stabilise.
- Out‑of‑sample testing – If you have a hold‑out set with known values, artificially mask them, impute, and measure error (e.g., RMSE).
If diagnostics reveal systematic discrepancies, revisit the imputation model: perhaps add auxiliary predictors, increase the number of imputations, or switch to a more flexible method (e.In practice, g. , random‑forest imputation via missForest).
6. Document Everything
A reproducible analysis notebook should contain:
- Missingness summary (tables & plots).
- Rationale for the chosen method (including assumptions about MCAR/MAR/MNAR).
- Code that performs detection, imputation, and model fitting.
- Diagnostic output confirming that imputed values behave plausibly.
- Impact assessment – Show how key results change (or stay stable) when using alternative handling strategies.
Real‑World Example: The “4 × y = 10” Scenario
Imagine a small engineering dataset recording the force (F) applied to a spring, the displacement (x), and the spring constant (k). The relationship follows Hooke’s law: F = k * x. A data entry reads:
| Observation | F (N) | x (m) | k (N/m) |
|---|---|---|---|
| 1 | 4 | ? | 10 |
Here the displacement x is missing. Because we know F and k, we can solve for the missing value analytically:
[ x = \frac{F}{k} = \frac{4}{10} = 0.4\ \text{m} ]
In this special case, the missing value is deterministic—the physics provides a perfect imputation. That said, most real datasets lack such a clean formula, which is why the broader toolbox described above is indispensable.
Common Pitfalls to Avoid
| Pitfall | Consequence | How to Prevent |
|---|---|---|
| Treating “0” as missing | Inflates or deflates means, especially for count data | Explicitly code missing as NA/NaN and keep zeros separate |
| Imputing without checking MCAR/MAR | Biased parameter estimates | Perform Little’s MCAR test or model missingness as a function of observed covariates |
| Using a single imputed value and ignoring uncertainty | Underestimates standard errors, over‑confident conclusions | Adopt multiple imputation or Bayesian posterior predictive draws |
| Dropping rows with a single missing entry in a high‑dimensional dataset | Massive loss of information | Prefer model‑based or nearest‑neighbor imputation when dimensionality is high |
| Failing to re‑encode categorical variables after imputation | Mis‑aligned factor levels, erroneous predictions | Re‑factor levels post‑imputation or use dedicated categorical imputation methods (e.g., catImpute in missRanger) |
Quick‑Reference Checklist
- Identify missing cells →
is.na/isnull. - Summarize proportion & pattern → heat‑maps, Little’s test.
- Diagnose mechanism (MCAR, MAR, MNAR).
- Select handling method (deletion, simple imputation, MI, model‑based).
- Implement with reproducible code.
- Validate via diagnostics and, if possible, external hold‑out.
- Document assumptions, code, and impact on results.
Conclusion
Missing values are an inevitable reality in any data‑driven endeavor. Far from being a nuisance, they are a diagnostic cue that tells you something about how the data were collected, recorded, or processed. By systematically detecting gaps, understanding the underlying missingness mechanism, and applying the right combination of deletion, simple imputation, or sophisticated multiple‑imputation techniques, you safeguard the integrity of your analyses Not complicated — just consistent..
Counterintuitive, but true.
The “4 × y = 10 missing value” illustration underscores two key lessons:
- Context matters – sometimes domain knowledge can supply a precise fill‑in; other times you must rely on statistical inference.
- Method matters – the choice between a quick mean substitution and a full Bayesian imputation will shape both point estimates and their uncertainty.
Armed with the workflow, tools, and cautionary notes presented here, you can now approach any dataset—whether a modest spreadsheet or a massive, multi‑source data lake—with confidence that missing values will be handled thoughtfully, transparently, and rigorously. Your conclusions will be stronger, your models more reliable, and your insights truly data‑driven Most people skip this — try not to..